Codeninja 7B Q4 How To Use Prompt Template
Codeninja 7B Q4 How To Use Prompt Template - I understand getting the right prompt format is critical for better answers. Here are all example prompts easily to copy, adapt and use for yourself (external link, linkedin) and here is a handy pdf version of the cheat sheet (external link, bp) to take. You need to strictly follow prompt. This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. Formulating a reply to the same prompt takes at least 1 minute: This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. If there is a </s> (eos) token anywhere in the text, it messes up. You need to strictly follow prompt templates and keep your questions short. Provided files, and awq parameters i currently release 128g gemm models only. These are the parameters and prompt i am using for llama.cpp: Chatgpt can get very wordy sometimes, and. These files were quantised using hardware kindly provided by massed compute. Hermes pro and starling are good chat models. Formulating a reply to the same prompt takes at least 1 minute: Here are all example prompts easily to copy, adapt and use for yourself (external link, linkedin) and here is a handy pdf version of the cheat sheet (external link, bp) to take. Are you sure you're using the right prompt format? We will need to develop model.yaml to easily define model capabilities (e.g. Known compatible clients / servers gptq models are currently supported on linux. You need to strictly follow prompt. There's a few ways for using a prompt template: In lmstudio, we load the model codeninja 1.0 openchat 7b q4_k_m. Hermes pro and starling are good chat models. Known compatible clients / servers gptq models are currently supported on linux. Available in a 7b model size, codeninja is adaptable for local runtime environments. Here are all example prompts easily to copy, adapt and use for yourself (external link, linkedin). If using chatgpt to generate/improve prompts, make sure you read the generated prompt carefully and remove any unnecessary phrases. This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. I understand getting the right prompt format is critical for better answers. This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. There's a few. Ensure you select the openchat preset, which incorporates the necessary prompt. This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. Gptq models for gpu inference, with multiple quantisation parameter options. Deepseek coder and codeninja are good 7b models for coding. Available in a 7b model size, codeninja is adaptable for local runtime environments. Chatgpt can get very wordy sometimes, and. 20 seconds waiting time until. In lmstudio, we load the model codeninja 1.0 openchat 7b q4_k_m. There's a few ways for using a prompt template: This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. Gptq models for gpu inference, with multiple quantisation parameter options. You need to strictly follow prompt templates and keep your questions short. Provided files, and awq parameters i currently release 128g gemm models only. Available in a 7b model size, codeninja is adaptable for local runtime environments. Formulating a reply to the same prompt takes at least 1 minute: Hermes pro and starling are good chat models. 20 seconds waiting time until. Users are facing an issue with imported llava: The tutorial demonstrates how to. These files were quantised using hardware kindly provided by massed compute. There's a few ways for using a prompt template: I'm testing this (7b instruct) in text generation web ui and i noticed that the prompt template is different than normal llama2. Hermes pro and starling are good chat models. Known compatible clients / servers gptq models are currently supported. Using lm studio the simplest way to engage with codeninja is via the quantized versions on lm studio. There's a few ways for using a prompt template: Users are facing an issue with imported llava: Ensure you select the openchat preset, which incorporates the necessary prompt. Available in a 7b model size, codeninja is adaptable for local runtime environments. I understand getting the right prompt format is critical for better answers. If there is a </s> (eos) token anywhere in the text, it messes up. This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. Deepseek coder and codeninja are good 7b models for coding. You need to strictly follow prompt. Are you sure you're using the right prompt format? The tutorial demonstrates how to. There's a few ways for using a prompt template: Provided files, and awq parameters i currently release 128g gemm models only. Description this repo contains gptq model files for beowulf's codeninja 1.0. Gptq models for gpu inference, with multiple quantisation parameter options. Chatgpt can get very wordy sometimes, and. We will need to develop model.yaml to easily define model capabilities (e.g. If there is a </s> (eos) token anywhere in the text, it messes up. Here are all example prompts easily to copy, adapt and use for yourself (external link, linkedin) and here is a handy pdf version of the cheat sheet (external link, bp) to take. Users are facing an issue with imported llava: Available in a 7b model size, codeninja is adaptable for local runtime environments. You need to strictly follow prompt. Are you sure you're using the right prompt format? Available in a 7b model size, codeninja is adaptable for local runtime environments. There's a few ways for using a prompt template: Thebloke gguf model commit (made with llama.cpp commit 6744dbe) a9a924b 5 months. This repo contains gguf format model files for beowulf's codeninja 1.0 openchat 7b. Hermes pro and starling are good chat models. I'm testing this (7b instruct) in text generation web ui and i noticed that the prompt template is different than normal llama2. These are the parameters and prompt i am using for llama.cpp:
TheBloke/CodeNinja1.0OpenChat7BAWQ · Hugging Face

RTX 4060 Ti 16GB deepseek coder 6.7b instruct Q4 K M using KoboldCPP 1.

fe2plus/CodeLlama7bInstructhf_PROMPT_TUNING_CAUSAL_LM at main
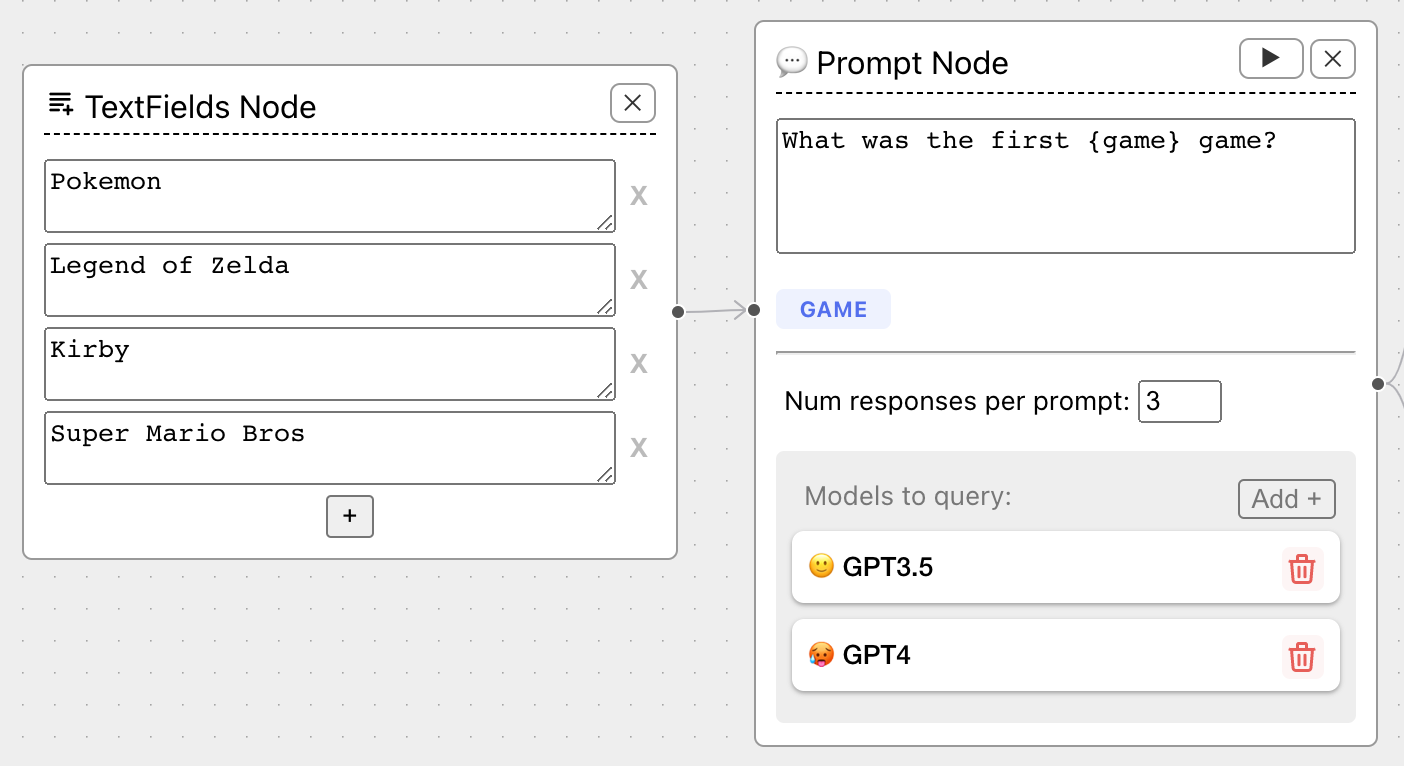
Prompt Templating Documentation

Beowolx CodeNinja 1.0 OpenChat 7B a Hugging Face Space by hinata97

Custom Prompt Template Example from Docs can't instantiate abstract

Add DARK_MODE in to your website darkmode CodeCodingJourney

How to use motion block in scratch Pt1 scratchprogramming codeninja
![]()
CodeNinja An AIpowered LowCode Platform Built for Speed Intellyx

TheBloke/CodeNinja1.0OpenChat7BGPTQ · Hugging Face
Ensure You Select The Openchat Preset, Which Incorporates The Necessary Prompt.
Provided Files, And Awq Parameters I Currently Release 128G Gemm Models Only.
Known Compatible Clients / Servers Gptq Models Are Currently Supported On Linux.
Formulating A Reply To The Same Prompt Takes At Least 1 Minute:
Related Post: